
セキュリティスキャナのインテグレーション
セキュリティスキャナをGitLabにインテグレーションすることは、エンドユーザーがGitLabプロジェクトをスキャンするためにCI設定ファイルに追加できるCIジョブの定義を提供することです。このCIジョブは、GitLabが指定したフォーマットで結果を出力する必要があります。これらの結果は、パイプラインビュー、マージリクエストウィジェット、セキュリティダッシュボードのようなGitLabの様々な場所で自動的に表示されます。
スキャンジョブは通常、スキャナとそのすべての依存関係を自己完結環境に含むDockerイメージに基づいています。
このページは、セキュリティスキャナを実装する CI ジョブを書くための要件とガイドライン、および Docker イメージの要件とガイドラインを文書化したものです。
ジョブの定義
このセクションでは、セキュリティスキャナのジョブ定義ファイルに追加するいくつかの重要なフィールドについて説明します。これらのフィールドおよびその他の利用可能なフィールドに関する完全なドキュメントは、CIのドキュメントで見ることができます。
名前
一貫性を保つため、スキャンジョブはスキャナの後に小文字で名前を付ける必要があります。ジョブ名はスキャンのタイプの後に付けます:
_dependency_scanning_container_scanning_dast_sast
例えば、”MySec “スキャナーに基づく依存スキャンジョブは、mysec_dependency_scanning という名前になります。
イメージ
image キーワードは、セキュリティスキャナを含むDocker イメージを指定するために使用します。
Script
script キーワードは、スキャナを実行するコマンドを指定するために使用します。script エントリを空のままにすることはできないため、スキャンを実行するコマンドを設定する必要があります。Dockerイメージの定義済みのENTRYPOINT 、CMD 、コマンドを渡さずに自動的にスキャンを実行することはできません。
ユーザーがスキャンを実行する前にプロジェクトを準備するためにこれに依存する可能性があるため、before_script をジョブ定義で使用すべきではありません。例えば、SASTや依存関係スキャンを実行する前に、特定のプロジェクトが必要とするシステムライブラリをインストールするためにbefore_script 。
同様に、after_script はユーザーによって上書きされる可能性があるため、ジョブ定義では使用しないでください。
ステージ
一貫性を保つため、スキャンジョブは可能な限りtest ステージに属するようにします。test がデフォルト値であるため、stage キーワードは省略できます。
フェイルセーフ
GitLab Securityのパラダイムに合わせるために、スキャンジョブは失敗したときにパイプラインをブロックしないように、allow_failure パラメータはtrue に設定します。
アーティファクト
スキャンジョブは、artifacts:reports キーワードを使用して、実行するスキャンのタイプに対応するレポートを宣言する必要があります。有効なレポートは以下のとおりです:
dependency_scanningcontainer_scanningdastapi_fuzzingcoverage_fuzzingsast
例えば、gl-sast-report.json という名前のファイルを生成し、SAST レポートとしてアップロードする SAST ジョブの定義を以下に示します:
mysec_sast:
image: registry.gitlab.com/secure/mysec
artifacts:
reports:
sast: gl-sast-report.json
gl-sast-report.json はファイルパスの例ですが、他のファイル名を使用することもできます。詳細については、「出力ファイル」セクションを参照してください。ファイル名ではなく、ジョブ定義のreports:sast キーで宣言されているため、SAST レポートとして処理されます。
ポリシー
AutoDevOpsのような特定のGitLabワークフローでは、CI/CD変数を定義して、指定されたスキャンを無効にする必要があることを示します。次のような変数を探すことで、これをチェックすることができます:
DEPENDENCY_SCANNING_DISABLEDCONTAINER_SCANNING_DISABLEDSAST_DISABLEDDAST_DISABLED
スキャナーの種類によって適切な場合は、カスタムスキャナーの実行を無効にする必要があります。
GitLab はCI_PROJECT_REPOSITORY_LANGUAGES 変数も定義しており、リポジトリ内の言語のリストを提供します。この値によって、スキャナの動作が変わったり変わらなかったりします。言語検出は今のところlinguist Ruby gem に依存しています。定義済みのCI/CD変数を参照してください。
ポリシーチェックの例
この例では、プロジェクトリポジトリに Java ソースコードが含まれ、dependency_scanning 機能が有効になっていない限り、カスタム依存関係スキャンジョブmysec_dependency_scanning をスキップする方法を示します:
mysec_dependency_scanning:
rules:
- if: $DEPENDENCY_SCANNING_DISABLED == 'true'
when: never
- if: $GITLAB_FEATURES =~ /\bdependency_scanning\b/
exists:
- '**/*.java'
追加のジョブポリシーは、ユーザーが必要に応じて設定する必要があります。例えば、事前に定義されたポリシーは、特定のブランチや特定のファイルセットが変更されたときにスキャンジョブをトリガーすべきではありません。
Dockerイメージ
Dockerイメージは、スキャナとそれに依存するすべてのライブラリやツールを組み合わせた自己完結型の環境です。スキャナをDockerイメージにパッケージ化することで、スキャナが実行される個々のマシンに関係なく、その依存関係と設定が常に存在するようになります。
イメージサイズ
CIインフラストラクチャによっては、CIがジョブを実行するたびにDockerイメージをフェッチする必要があるかもしれません。スキャンジョブを高速に実行し、帯域幅の浪費を避けるために、Dockerイメージはできるだけ小さくする必要があります。50MB以下を目指してください。それが不可能な場合は、DVD-ROMのサイズである1.46GB以下に抑えるようにしてください。
スキャナが完全に機能する Linux 環境を必要とする場合は、Debian“slim” ディストリビューションまたはAlpine Linuxを使用することをお勧めします。可能であれば、FROM scratch 命令を使用してゼロからイメージをビルドし、スキャナが必要とするすべてのライブラリをコンパイルすることをお勧めします。多段階ビルドもイメージを小さく保つのに役立つかもしれません。
イメージのサイズを小さく保つには、Dockerイメージのレイヤーを分析するためにdiveを使用し、追加の肥大化の原因を特定することを検討してください。
イメージからファイルを削除するのが難しい場合もあります。このような場合は、Zstandardを使用してファイルや大きなディレクトリを圧縮することを検討してください。Zstandard にはさまざまな圧縮レベルがあり、解凍速度にほとんど影響を与えることなく、画像のサイズを小さくすることができます。圧縮されたディレクトリは、画像の起動と同時に自動的に解凍すると便利です。Dockerイメージの/etc/bashrc 、または特定のユーザーの$HOME/.bashrc 。後者のオプションを選択した場合は、Bashログインシェルを起動するようにエントリーポイントを変更することを忘れないでください。
以下はその例です:
- https://gitlab.com/gitlab-org/security-products/license-management/-/blob/0b976fcffe0a9b8e80587adb076bcdf279c9331c/config/install.sh#L168-170
- https://gitlab.com/gitlab-org/security-products/license-management/-/blob/0b976fcffe0a9b8e80587adb076bcdf279c9331c/config/.bashrc#L49
画像タグ
Docker Official Imagesプロジェクトで文書化されているように、バージョン番号タグには、ユーザーが特定のシリーズの「最新」リリースを簡単に参照できるようなエイリアスを付けることが強く推奨されています。Docker Taggingも参照してください:Dockerイメージのタグ付けとバージョン管理のベストプラクティスも参照してください。
コマンドライン
スキャナーは、環境変数を入力として受け取り、(ジョブ定義に基づいて)レポートとしてアップロードされるファイルを生成するコマンドラインツールです。また、標準出力と標準エラーストリームにテキスト出力を生成し、ステータスコードとともに終了します。
変数
CI/CD変数はすべて環境変数としてスキャナーに渡されます。スキャンされたプロジェクトは定義済みのCI/CD変数によって記述されます。
SASTと依存関係のスキャン
SAST と Dependency Scanning スキャナは、CI_PROJECT_DIR CI/CD 変数で指定されたプロジェクトディレクトリのファイルをスキャンしなければなりません。
コンテナの脆弱性スキャン
公式のContainer Scanning for GitLabとの一貫性を保つため、スキャナはCI_APPLICATION_REPOSITORY とCI_APPLICATION_TAG で指定された名前とタグを持つDockerイメージをスキャンしなければなりません。 CI/CD変数DOCKER_IMAGE が提供された場合、CI_APPLICATION_REPOSITORY とCI_APPLICATION_TAG 変数は無視され、代わりにDOCKER_IMAGE 変数で指定されたイメージがスキャンされます。
提供されない場合、CI_APPLICATION_REPOSITORY はデフォルトで$CI_REGISTRY_IMAGE/$CI_COMMIT_REF_SLUG になるはずです。これは定義済みの CI/CD 変数の組み合わせです。CI_APPLICATION_TAG はデフォルトでCI_COMMIT_SHA になるはずです。
スキャナは変数DOCKER_USER とDOCKER_PASSWORD を使ってDockerレジストリに署名する必要があります。これらが定義されていない場合、スキャナはデフォルト値としてCI_REGISTRY_USER とCI_REGISTRY_PASSWORD を使う必要があります。
設定ファイル
スキャナはCI_PROJECT_DIR を使って特定の設定ファイルを読み込むことができますが、設定はファイルではなく CI/CD 変数として公開することを推奨します。
出力ファイル
GitLab CI/CD にアップロードされたアーティファクトと同様に、スキャナによって生成された Secure レポートはCI_PROJECT_DIR CI/CD 変数で指定されたプロジェクトディレクトリに書き込まれなければなりません。
出力ファイルにはスキャンの種類にちなんだ名前を付け、gl- をプレフィックスとして使用することをお勧めします。Secure レポートはすべて JSON ファイルであるため、ファイルの拡張子には.json を使用することを推奨します。たとえば、依存関係スキャンレポートの推奨ファイル名はgl-dependency-scanning.json です。
ジョブ定義のartifacts:reports キーワードは、セキュリティレポートが書き込まれるファイルパスと一致している 必要があります。例えば、依存関係スキャン分析ツールがそのレポートを CI プロジェクトディレクトリに書き込む場合、このレポートファイル名がdepscan.json である場合は、artifacts:reports:dependency_scanning をdepscan.json に設定する必要があります。
終了コード
POSIXの終了コード標準に従い、スキャナは成功の場合は0 、失敗の場合は1 。成功には脆弱性が見つかった場合も含まれます。
CI ジョブが失敗した場合、たとえジョブが失敗を許可していたとしても、セキュリティレポートの結果は GitLab に取り込まれません。しかし、レポートのアーティファクトは GitLab にアップロードされ、パイプラインセキュリティタブからダウンロードできます。
伐採
スキャナーはエラーメッセージや警告をログに記録し、ユーザーがCIスキャンのジョブのログを見ることで、設定ミスやインテグレーションに関する問題を簡単に調査できるようにする必要があります。
スキャナは、ANSIエスケープコードを使用して、Unix標準出力と標準エラーストリームに書き込むメッセージを色分けすることができます。エラーの報告には赤、警告には黄、通知には緑を使うことを推奨します。また、エラーメッセージには[ERRO] を、警告には[WARN] を、通知には[INFO] を先頭に付けることをお勧めします。
ロギング・レベル
ログレベルがSECURE_LOG_LEVEL CI/CD変数で設定されたものよりも低い場合、スキャナはログメッセージをフィルタリングする必要があります。例えば、SECURE_LOG_LEVEL がerrorに設定されている場合、info とwarn メッセージはスキップされます。許容される値は以下の通りです:
fatalerrorwarninfodebug
デバッグ時に有用な冗長なロギングにはdebug レベルを使うことを推奨します。SECURE_LOG_LEVEL のデフォルト値はinfo に設定する必要があります。
コマンドラインを実行するとき、スキャナは、コマンドラインとその出力をログに記録するためにdebug レベルを使用する必要があります。コマンドラインが失敗した場合、error ログレベルでログに記録されるべきです。これにより、ログレベルをdebug に変更してスキャンジョブを再実行することなく、問題をデバッグすることが可能になります。
共通logutil パッケージ
goと commonを使用している場合は、Logrusと commonのlogutil パッケージ 、Logrus用のフォーマッタを設定することをお勧めします。logutil READMEを参照してください。
レポート
レポートは、脆弱性と可能な改善策を組み合わせたJSONドキュメントです。
このドキュメントでは、レポート JSON 形式の概要と、インテグレータがフィールドを設定するのに役立つ推奨事項や例を示します。この形式については、SAST、DAST、依存関係スキャン、コンテナ・スキャンのドキュメントで詳しく説明しています。
これらのスキャナのスキーマはここで見つけることができます:
レポートの検証
GitLab 15.0 で導入されました。
スキャナによって生成されたレポーターが、レポートで宣言されたスキーマバージョンに対するバリデーションをパスすることを確認する必要があります。バリデーションに合格しないレポーターはGitLabに取り込まれず、対応するパイプラインにエラーメッセージが表示されます。
非推奨バージョンのセキュアレポートスキーマを使用しているレポーターは取り込まれますが、対応するパイプラインに警告メッセージが表示されます。この警告が表示された場合は、利用可能な最新のスキーマを使用するようにアナライザを更新してください。
スキーマバージョンの非推奨期間が過ぎると、ファイルは GitLab から削除されます。削除されたバージョンを宣言したレポーターは拒否され、対応するパイプラインにエラーメッセージが表示されます。
もしレポートがベンダPATCH リングされたスキーマのバージョンと一致 PATCHしないバージョンを使用しているPATCH 場合、最新のベンダリングされたバージョンに対して検証されます PATCH。例えば、レポートのバージョンが 15.0.23 で、最新の vendored バージョンが 15.0.6 の場合、レポートはバージョン 15.0.6 に対して検証されます。
GitLabはjson_schemer gemを使ってバリデーションを行います。
レポートのバリデーションに関する継続的な改善は、このエピックで追跡しています。とりあえず、どのバージョンがサポートされているかはソースコードで確認できます。あなたのインスタンスに合った正しいバージョンを選ぶことを忘れないでください、例えばv15.7.3-ee 。
ローカルでの検証
GitLabでアナライザーを実行する前に、アナライザーが生成したレポーターが宣言されたスキーマのバージョンに準拠しているかどうかを検証してください。
以下のスクリプトを使って、指定したスキーマに対してJSONファイルを検証します。
require 'bundler/inline'
gemfile do
source 'https://rubygems.org'
gem 'json_schemer'
end
require 'json'
require 'pathname'
raise 'Usage: ruby script.rb <security schema file name> <report file name>' unless ARGV.size == 2
schema = JSONSchemer.schema(Pathname.new(ARGV[0]))
report = JSON.parse(File.open(ARGV[1]).read)
schema_validation_errors = schema.validate(report).map { |error| JSONSchemer::Errors.pretty(error) }
puts(schema_validation_errors)
- レポートのタイプと宣言されたバージョンに一致する適切なスキーマをダウンロードしてください。たとえば、
container_scanningレポート・スキーマのバージョン15.0.6は、https://gitlab.com/gitlab-org/security-products/security-report-schemas/-/raw/v15.0.6/dist/container-scanning-report-format.json?inline=falseにあります。 - 上記の Ruby スクリプトを、例えば
validate.rbのようなファイルに保存します。 - スキーマとレポート・ファイル名を順番に引数として渡して、スクリプトを実行します。例えば
- 内部Rubyインタプリタを使用する場合:
ruby validate.rb container-scanning-format_15-0-6.json gl-container-scanning-report.json. - Dockerを使用します:
docker run -it --rm -v $(pwd):/ci ruby:3 ruby /ci/validate.rb /ci/container-scanning-format_15-0-6.json /ci/gl-container-scanning-report.json
- 内部Rubyインタプリタを使用する場合:
- 検証エラーが画面に表示されます。GitLabがレポートを取り込む前に、これらのエラーを解決する必要があります。
レポートフィールド
バージョン
このフィールドは、使用しているセキュリティ・レポート・スキーマのバージョンを指定します。使用するバージョンについては、リリースを参照してください。
GitLab 14.10以降では、GitLabはこの値で指定されたスキーマのバージョンに対してレポートを検証します。GitLabがサポートしているバージョンは、gitlab/ee/lib/ee/gitlab/ci/parsers/security/validators/schemas 。
脆弱性
レポートのvulnerabilities フィールドは脆弱性オブジェクトの配列です。
ID
このid フィールドは脆弱性の一意な識別子 idです。id 修正オブジェクトから修正された脆弱性を参照するために使用されます。UUID を生成し、 idフィールドのid 値として使用することをお勧めします id。
カテゴリ
category フィールドの値はレポートタイプと一致します:
dependency_scanningcontainer_scanningsastdast
スキャン
scan フィールドは、スキャン自体に関するメタ情報を埋め込むオブジェクトです。スキャンを実行したanalyzer とscanner 、スキャンが実行したstart_time とend_time 、スキャンのstatus (「成功」または「失敗」のいずれか)。
analyzer 、scanner の両フィールドは、人間がid読める id name idと技術的な idを埋め込んだオブジェクトです。他のインテグレーターが提供する他のアナライザーやidスキャナーと id衝突しないようにしてください。
スキャンの一次識別子
scan.primary_identifiers フィールドは、一次識別子の配列を含むオプションのフィールドです)。これは、アナライザがスキャンを実行したすべてのルールセットの完全なリストです。
あるスキャンのVulnerabilities 配列が空の場合でも、このオプションフィールドには、どのルールが実行されたかをRailsアプリケーションに通知するための潜在的な識別子の完全なリストを含める必要があります。
プライマリ識別子が含まれていない場合、Railsアプリケーションは以前に検出された脆弱性を関連性がないものとして自動的に解決することができます。
名前、メッセージ、説明
name とmessage フィールドには、脆弱性の短い説明が含まれています。description フィールドには詳細が記載されています。
name フィールドはコンテクストフリーで、脆弱性が発見された場所に関する情報を含みませんが、message はその場所を繰り返すかもしれません。
視覚的な例として、このスクリーンショットは、パイプラインビューの一部として脆弱性を表示するときに、これらのフィールドが使用される場所を強調しています。
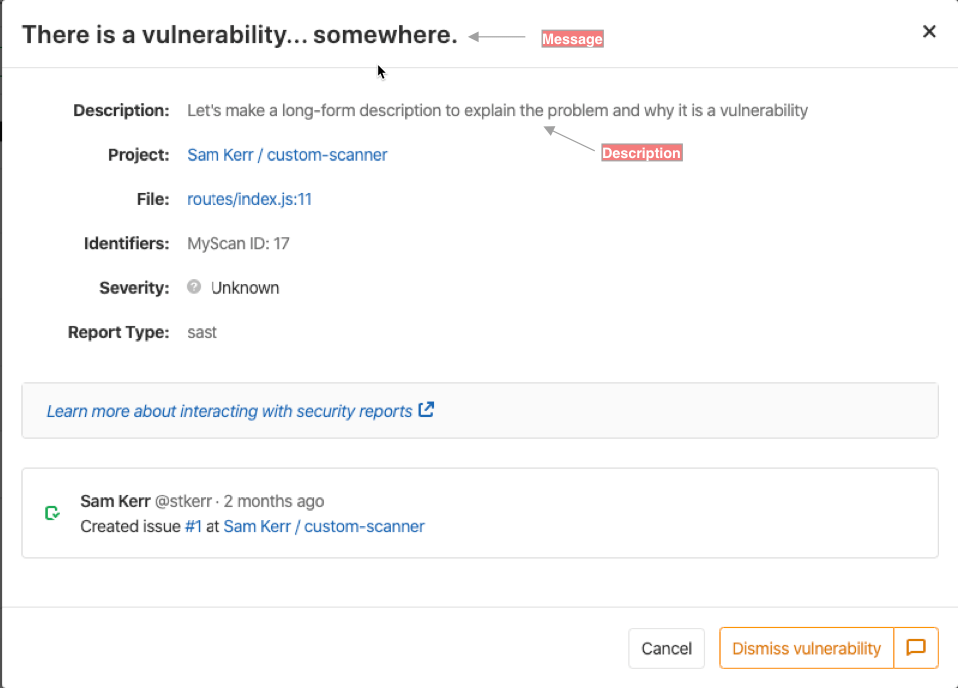
例えば、依存関係スキャンによってレポーターされた脆弱性のmessage は、脆弱性の依存関係の情報を提供しますが、これは脆弱性のlocation フィールドとは冗長です。name フィールドが望ましいですが、message フィールドは、脆弱性のタイトルからコンテキスト/場所を削除できない場合に使用されます。
message がlocation フィールドと重複しています:
{
"location": {
"dependency": {
"package": {
"name": "debug"
}
}
},
"name": "Regular Expression Denial of Service",
"message": "Regular Expression Denial of Service in debug",
"description": "The debug module is vulnerable to regular expression denial of service
when untrusted user input is passed into the `o` formatter.
It takes around 50k characters to block for 2 seconds making this a low severity issue."
}
脆弱description 性がどのように機能するかを説明したり、エクスプロイトに関するコンテキストを与えるかもしれません description。description 脆弱性オブジェクトの他のフィールドを繰り返してはいけません。特に description、location (何が影響を受けるか)やsolution (どのようにリスクを軽減するか)を繰り返してはなりません。
解答
solution フィールドを使用して、特定された脆弱性の修正方法やリスクの軽減方法をユーザーに指示することができます。エンドユーザーはこのフィールドを操作しますが、GitLab は自動的にremediations オブジェクトを処理します。
識別子
identifiers 配列は検出された脆弱性を記述します。識別子オブジェクトのtype とvalue フィールドは、2 つの識別子が同じかどうかを判別するために使用されます。ユーザー・インタフェースは、オブジェクトのname とurl フィールドを使用して識別子を表示します。
GitLabスキャナがすでに定義している識別子を使うことをお勧めします:
| 識別子 | 種類 | 値の例 |
|---|---|---|
| CVE | cve | CVE-2019-10086 |
| CWE | cwe | CWE-1026 |
| エルザ | elsa | ELSA-2020-0085 |
| OSVD | osvdb | OSVDB-113928 |
| OWASP | owasp | A01:2021-壊れたアクセス制御設計 |
| RHSA | rhsa | RHSA-2020:0111 |
| USN | usn | USN-4234-1 |
| WASC | wasc | WASC-19 |
上記の汎用識別子は共通ライブラリで定義されており、GitLabがメンテナーとして管理しているいくつかのアナライザで共有されています。必要に応じて、新しい汎用識別子を貢献することができます。また、アナライザはベンダー固有の識別子や製品固有の識別子を生成することがありますが、これらは共通ライブラリには含まれません。
identifiers 配列の最初の項目はプライマリ識別子と呼ばれ、新しいコミットがリポジトリにプッシュされたときに脆弱性を追跡するために使われます。
すべての脆弱性に CVE があるわけではなく、1 つの CVE が複数回識別されることもあります。そのため、CVE は安定した識別子ではなく、脆弱性を追跡する際にはそのように仮定すべきではありません。
脆弱性の識別子の最大数は20に設定されています。脆弱性に 20 個以上の識別子がある場合、システムは最初の 20 個だけを保存します。[パイプラインセキュリティ]](../../user/application_security/vulnerability_report/pipeline.md#view-vulnerabilities-in-a-pipeline)タブの脆弱性にはこの制限が適用されず、レポートアーティファクトに存在するすべての識別子が表示されます。
詳細
details フィールドは、脆弱性情報を表示するときに表示されるさまざまな内容要素をサポートするオブジェクトです。様々なデータ要素の例は、security-reports リポジトリで見ることができます。
設置場所
location は脆弱性が検出された場所を示します。場所の形式はスキャンの種類によって異なります。
GitLab 内部では、location のいくつかの属性を抽出してlocation fingerprint を生成します。これは、新しいコミットがリポジトリにプッシュされたときに脆弱性を追跡するために使われます。ロケーションフィンガープリントを生成するために使われる属性もスキャンの種類によって異なります。
依存関係の脆弱性スキャン
依存性スキャニングの脆弱性のlocation は、dependency とfile から構成されます。dependency オブジェクトは、影響を受けるpackage と依存性versionを記述します。package は、影響を受けるライブラリ/モジュールのname を埋め込みます。file は、影響を受ける依存性を宣言する依存性ファイルのパスです。
例えば、以下は npm パッケージhandlebarsのバージョン4.0.11 に影響する脆弱性のlocation オブジェクトです:
{
"file": "client/package.json",
"dependency": {
"package": {
"name": "handlebars"
},
"version": "4.0.11"
}
}
この影響を受ける依存関係は、npm または yarn によって処理される依存関係ファイルであるclient/package.json にリストされています。
依存性スキャンの脆弱性の位置フィンガープリントはfile とパッケージname を結合するので、これらの属性は必須です。他の属性はすべてオプションです。
コンテナの脆弱性スキャン
依存関係スキャンと同様に、コンテナスキャンの脆弱性のlocation には、dependency とfile があります。 また、operating_system フィールドもあります。
例えば、以下は Debian パッケージglib2.0 のバージョン2.50.3-2+deb9u1 に影響する脆弱性のlocation オブジェクトです:
{
"dependency": {
"package": {
"name": "glib2.0"
},
},
"version": "2.50.3-2+deb9u1",
"operating_system": "debian:9",
"image": "registry.gitlab.com/example/app:latest"
}
影響を受けるパッケージは Docker イメージregistry.gitlab.com/example/app:latest をスキャンした際に見つかりました。この Docker イメージはdebian:9 (Debian Stretch) に基づいています。
コンテナスキャン脆弱性のロケーションフィンガープリントは、operating_system とパッケージname を組み合わせたものなので、これらの属性は必須です。image も必須です。その他の属性はすべてオプションです。
SAST
SAST脆弱性のlocation は、影響を受けるファイルのパスを示すfile と、影響を受ける行番号を示すstart_line フィールドを持たなければなりません。また、end_line 、class 、method。
例えば、src/main/java/com/gitlab/example/App.java の41 行目、com.gitlab.security_products.tests.App Java クラスのgenerateSecretToken メソッドで見つかったセキュリティ欠陥のlocation オブジェクトです:
{
"file": "src/main/java/com/gitlab/example/App.java",
"start_line": 41,
"end_line": 41,
"class": "com.gitlab.security_products.tests.App",
"method": "generateSecretToken1"
}
SAST 脆弱性の位置フィンガープリントは、file 、start_line 、end_line を組み合わせますので、これらの属性は必須です。他の属性はすべてオプションです。
脆弱性の追跡とマージ
ユーザーは脆弱性についてフィードバックすることができます:
- 脆弱性が自分のプロジェクトに当てはまらなければ、その脆弱性を否定することもできます。
- 脅威の可能性があれば、脆弱性のイシューを作成するかもしれません。
GitLab は、新しい Git コミットがリポジトリにプッシュされたときにユーザーのフィードバックが失われないように、脆弱性を追跡します。脆弱性はUUIDv5 ダイジェストを使って追跡されます。 ダイジェストは4つの属性のSHA-1 ハッシュによって生成されます:
- レポートの種類
- 一次識別子
- ロケーション・フィンガープリント
- プロジェクトID
今のところ、GitLabは新しいGitコミットがプッシュされたときに脆弱性の位置が変わるとその脆弱性を追跡することができず、その結果ユーザーのフィードバックが失われてしまいます。例えば、SAST 脆弱性に関するユーザーフィードバックは、影響を受けるファイルの名前が変更されたり、影響を受ける行が下に移動したりすると失われます。これはイシュー#7586でアドレス指定されています。
重複排除処理も参照してください。
深刻度
severity フィールドは、脆弱性がソフトウェアに与える影響の程度を記述します。深刻度は、セキュリティダッシュボードで脆弱性を並べ替えるために使用されます。
深刻度の範囲はInfo からCritical までですが、Unknown.有効な値は UnknownInfo,Low,Medium,High, またはCritical
Unknown 値は、実際の値を決定するためにデータが利用できないことを意味します。したがって、high 、medium、lowの可能性があり、調査が必要です。利用可能な SAST アナライザと現在利用可能なデータのChartを用意しました。
改善策
レポートのremediations フィールドは、修復オブジェクトの配列です。各修正には、脆弱性のセットを解決するために適用できるパッチが記述されています。
以下に、修復を含むレポートの例を示します。
{
"vulnerabilities": [
{
"category": "dependency_scanning",
"name": "Regular Expression Denial of Service",
"id": "123e4567-e89b-12d3-a456-426655440000",
"solution": "Upgrade to new versions.",
"scanner": {
"id": "gemnasium",
"name": "Gemnasium"
},
"identifiers": [
{
"type": "gemnasium",
"name": "Gemnasium-642735a5-1425-428d-8d4e-3c854885a3c9",
"value": "642735a5-1425-428d-8d4e-3c854885a3c9"
}
]
}
],
"remediations": [
{
"fixes": [
{
"id": "123e4567-e89b-12d3-a456-426655440000"
}
],
"summary": "Upgrade to new version",
"diff": "ZGlmZiAtLWdpdCBhL3lhcm4ubG9jayBiL3lhcm4ubG9jawppbmRleCAwZWNjOTJmLi43ZmE0NTU0IDEwMDY0NAotLS0gYS95Y=="
}
]
}
要約
summary フィールドは脆弱性の修正方法の概要です。このフィールドは必須です。
修正された脆弱性
fixes フィールドは、修復によって修正された脆弱性を参照するオブジェクトの配列です。fixes[].id には、修正された脆弱性の一意の識別子が含まれています。このフィールドは必須です。
差分
diff フィールドは、git applyと互換性のある、base64 エンコードされた修復コードの差分です。このフィールドは必須です。